Vorige week zag ik midden in een review ineens drie lege placeholders waar AI-afbeeldingen hadden moeten staan. Wat bleek? OpenAI had de oude DALL-E-modellen uitgefaseerd. Geen drama, dacht ik: even een snelle hotfix naar Azure OpenAI in West Europe. Maar dat kon niet eens. Het model was daar gewoon niet beschikbaar. Mijn ‘nette migratie’ viel in één keer in duigen.
Ik dacht dat ik een modelprobleem had. In werkelijkheid had ik een provider-strategieprobleem.
En tegelijk vragen klanten al maanden hetzelfde: “Draait de AI op een EU-server?” Mijn antwoord was steeds braaf “staat op de roadmap”. Twee signalen, één conclusie. Blind gokken op één vaste AI-provider is een risico dat je als SaaS-bedrijf niet zou moeten willen lopen.
Ik dacht dat ik een modelprobleem had. In werkelijkheid had ik een provider-strategieprobleem.
Het bouwen van de routering zelf was het makkelijke deel: een factory in Semantic Kernel en een stukje UI voor de deployment-opties. Het echte werk begon daarna pas. EU-compliance en governance. Datzelfde lock-in zie je trouwens ook aan de kostenkant, waar één provider je net zo goed klem kan zetten.
Waarom is een EU-regio nog geen EU-only?
Per provider moet je de DPA, de subverwerkerslijst en de deployment-opties opnieuw uitpluizen. Neem Azure OpenAI. Je kiest netjes een Europese regio voor je EU-residency, zeg Sweden Central. Klaar, denk je.
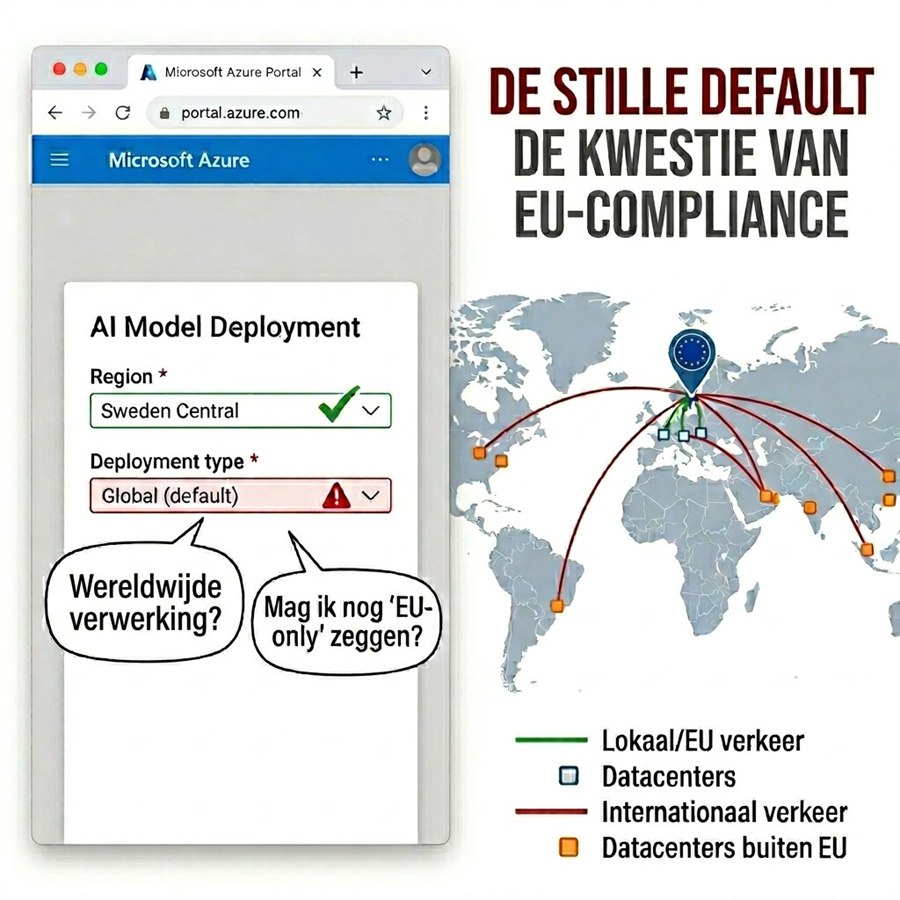
Want als het deployment-type op de default ‘Global’ blijft staan, kunnen prompts en responses wereldwijd verwerkt worden. In elke Azure-regio waar het model beschikbaar is. Er komt geen foutmelding. Geen compliance-alarm. Alleen een default die je juridisch niet ongezien wilt laten passeren.
Je moet dus expliciet naar het deployment-type kijken. ‘Data Zone Standard’ houdt de verwerking binnen de EU Data Boundary (de EU-lidstaten plus Noorwegen, IJsland en Liechtenstein). ‘Standard’ pint het vast op één vaste regio. ‘Global’ doet geen van beide.
Wat vraagt providerkeuze van je governance?
Zodra klanten zelf een provider mogen kiezen, wordt governance ineens een stuk explicieter. Je moet per klant kunnen aantonen welk model de output genereerde, dus audit-trails. Je krijgt te maken met verschillende retentie- en loggingregels per provider. En je moet consent-flows inrichten voor die regiokeuzes.
Voor een .NET-SaaS betekent dat: de providerkeuze, het deployment-type en het gebruikte model wil je vastleggen bij elke AI-call, niet achteraf reconstrueren. Een auditvraag komt zelden op een handig moment.
Waarom moet je prompts per provider opnieuw valideren?
Dezelfde prompt gedraagt zich per provider anders. Wat op GPT-5.x netjes binnen je guardrails blijft, geeft op Claude of Mistral soms net andere output. En dan krijg je niet meer automatisch wat je dacht getest te hebben.
Het gaat dus niet om één promptset die je onderhoudt. Je valideert het gedrag opnieuw per model, per provider, en weer bij iedere model-upgrade. Een prompt is daarmee een onderdeel van je kwaliteits- en complianceketen geworden, geen los stukje tekst meer.
Multi-provider maakt vooral zichtbaar hoeveel governance, validatie en compliance je eigenlijk al nodig had.
Wat betekent dit voor je AI-strategie?
Multi-provider gaat dus niet alleen over beschikbaarheid, over die ene keer dat een model ineens verdwijnt. Het maakt vooral zichtbaar hoeveel governance, validatie en compliance je eigenlijk al nodig had. De routering bouw je in een dag. De rest is het echte werk.
De stille default in je AI-pipeline is jouw keuze. Ook als je hem nooit bewust gemaakt hebt. En die keuze blijft niet stil. Niet als klanten vragen waar hun data heen gaat. Niet als een auditor er later naar kijkt en ‘EU-regio’ geen ‘EU-only’ blijkt.
Welke AI-aanname bleek bij jullie ineens een governance-risico?